实验概述¶
温(守)馨(住)提(红)示(线)
本课程实验已引入代码自动查重系统,请同学们保持学术诚信!
关于第二次实验课考核
我们将在第四次实验课进行第二次实验现场验收:
-
验收内容 :
- Lab2:进程与系统调用
- Lab3:锁机制的应用
-
验收目的 :考察同学们是否是自己完成的实验代码,而不是“复制拷贝”。
-
验收形式 :助教与同学们进行一对一问答
请同学们认真对待!
课程复习和预习要求
本节实验与理论课的 “多线程” 、 “信号量” 和 “死锁” 这三章课程内容相关,请同学们复习这三章课程内容。
在做实验之前,请同学们阅读xv6 book的以下章节及相关源代码:
- [1] xv6 book, Chapter 6 Locking (锁)
- [2] xv6 book, 3.5 Code: Physical memory allocator(物理内存分配器)
- [3] xv6 book, Chapter 8 File system:8.1 Overview ~ 8.3 Code: Buffer cache(磁盘缓存)
实验背景
锁起到了保护作用,让一些关键的数据结构在并行环境下仍能保持一致性。
本实验旨在优化xv6操作系统中的内存分配器与磁盘缓存机制,通过为它们各自设计更精细的锁策略,在保证正确性的前提下,显著减少锁争用,从而提升多核CPU下的并行性能。
1. 实验目的¶
- 了解Lock的实现原理,理解CPU为Lock的实现提供的支持。
- 理解xv6的内存分配器kalloc以及磁盘缓存buffer cache的工作原理,掌握Lock在xv6中内存分配器/磁盘缓存中的作用。
- 掌握锁竞争对程序并行性的影响。
- 学习减少锁竞争的方法。
2. 实验学时¶
本实验为4学时。
3. 实验内容及要求¶
请先同步上游远程仓库,并注意切换到lock分支进行试验
本次实验基于 lock 分支,请同学们参考“Lab2:进程与系统调用”的3.1 切换分支进行切换。
3.1 任务一:内存分配器(Memory allocator)¶
- 背景:当前 XV6 使用 单一链表 + 全局锁(kmem.lock 管理物理内存。多核并发调用 kalloc() 时,极易发生锁竞争,导致性能下降。
-
目标:优化 XV6 的物理内存分配器(主要位于
kernel/kalloc.c),为每个 CPU 核心维护独立的空闲页链表,以降低多核环境下的锁争用。 -
优化思路:
- 为每个 CPU 核分配独立的空闲内存链表,每个链表配备专属锁(避免全局锁竞争);
- 设计 “内存窃取” 机制:当某 CPU 核的本地链表内存不足时,可尝试从其他 CPU 核的链表中获取内存块(此过程可能引发短暂锁争用,但远低于全局锁的竞争频率)。
3.1.1 测评程序kalloctest说明¶
kalloctest(见user/kalloctest.c)程序包含两个测试场景:
- (1) test1:创建多进程在不同 CPU 核上并发执行kalloc()(内存申请)和kfree()(内存释放),模拟高并发内存操作场景,测量锁争用程度;
- (2) test2:在单进程内测试所有空闲内存的获取与释放,验证基础功能正确性。
锁争用的测量方式:
kalloctest程序通过statistics()函数读取内核统计信息,输出关键指标:
#acquire():锁的请求总次数;#fetch-and-add:CPU 自旋等待锁的次数(直接反映锁争用激烈程度)。
优化前的典型输出如下:
$ kalloctest
start test1
test1 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 46375 #acquire() 433016
lock: bcache: #fetch-and-add 0 #acquire() 1242
--- top 5 contended locks:
lock: kmem: #fetch-and-add 46375 #acquire() 433016
lock: proc: #fetch-and-add 21429 #acquire() 170067
lock: virtio_disk: #fetch-and-add 13306 #acquire() 114
lock: proc: #fetch-and-add 6023 #acquire() 170143
lock: proc: #fetch-and-add 3661 #acquire() 170147
tot= 46375
test1 FAIL // 锁争用剧烈
start test2
total free number of pages: 32499 (out of 32768)
.....
test2 OK // 功能正确性验证通过
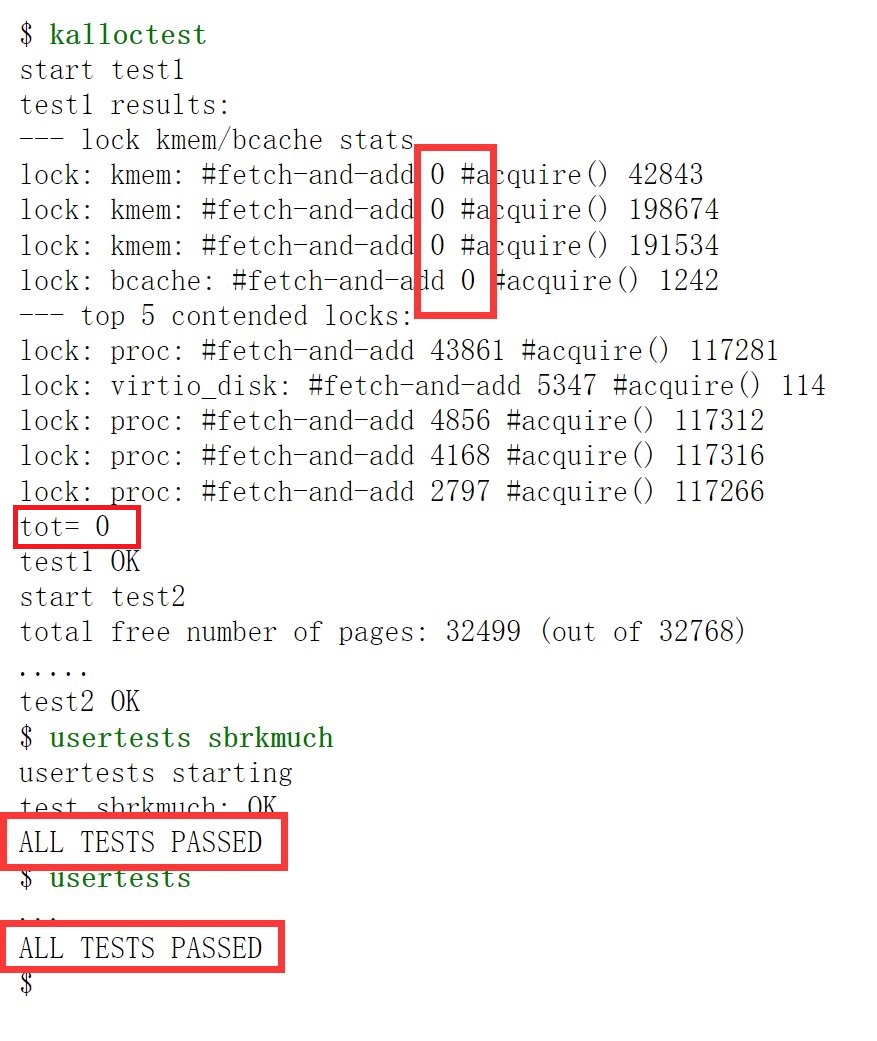
其中,test1 FAIL表明kmem锁竞争剧烈,而test2 OK说明基础内存管理功能正常。
"lock: kmem"、"lock: bcache"、"lock: proc" 等指示了锁的类型。例如, lock: kmem: #fetch-and-add 46375 #acquire() 433016 表明kmem.lock被请求433,016次,其中46,375次遭遇竞争需要自旋等待。
这些计数来自于在kalloctest调用的ntas(),它通过执行statistics()函数,打开"statistics"设备文件,获取内核打印的那些针对kmem和bcache锁( 本实验的重点 )及5个竞争最激烈的锁的计数(见kernel/spinlock.c中的statslock())。关于#acquire和#fetch-and-add的计数算法见测评程序kalloctest对锁的检测。
如果存在锁争用,fetch-and-add的数量将会很高,因为在acquire()获得锁之前要进行许多循环迭代,"statistics"设备文件会返回kmem和bcache锁的#test-and-set的总和(也就是tot的值,即没有获取到此锁的次数)。
3.1.2 具体要求¶
1) 新增锁需通过initlock()初始化,且命名必须以kmem为前缀;
2) 优化后运行kalloctest,查看实现的代码是否减少了锁争用(tot没有获取到此锁的次数小于10则为通过);
3) 运行 usertests sbrkmuch 以测试修改代码后系统是否仍可以分配所有的内存;
4) 运行usertests,确保其能能够全部通过;
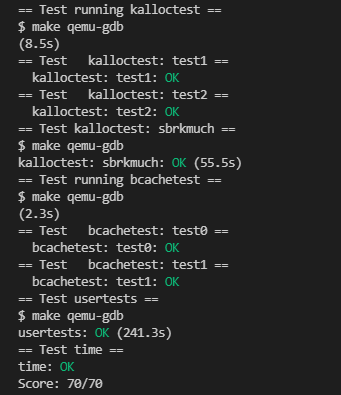
5) kalloctest和usertests的输出如下图(锁争用的次数大大减少),具体的数据会有所差别:
3.2 任务二:磁盘缓存(Buffer cache)¶
- 核心目标:重构磁盘缓存管理机制(主要修改
kernel/bio.c),通过多锁策略替代当前的全局bcache.lock,减少高并发场景下的锁争用。
磁盘缓存是进程间共享的关键资源,xv6 原生实现通过单把bcache.lock保护缓存块访问。当多进程密集读写文件时,会频繁竞争该锁,导致性能瓶颈。
本任务需优化缓存块的管理逻辑,通过多锁划分(如哈希桶分区、按缓存块粒度加锁等策略),使不同缓存块的操作可并行进行,从而降低锁争用。
3.2.1 测评程序bcachetest说明¶
测评程序bcachetest(见user/bcachetest.c)通过创建多个进程重复去读取不同的文件,从而造成bcache.lock锁争用。
实验前(即未修改前),测评程序bcachetest的输出如下:
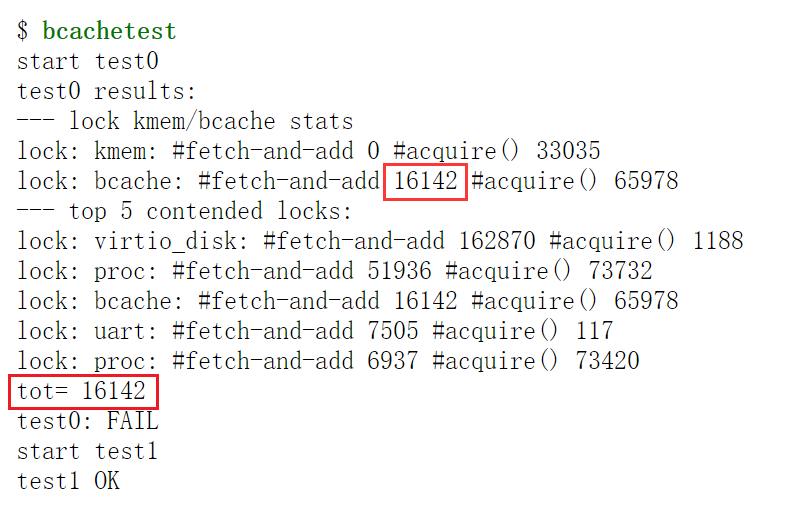
可以看到,bcache的fetch-and-add值非常大,说明磁盘缓存锁的争用非常严重。
修改buffer cache的设计后,所有锁的fetch-and-add的数目应当接近于0。
3.2.2 具体要求¶
关于bcache实验的约束条件
本实验要求大家在XV6原版的bcache基础上,修改磁盘缓存块列表的管理机制,主要修改kernel/bio.c。也就是,在原有的磁盘缓存大小的基础上,可采用多个哈希桶、时间戳、或CLOCK算法等优化策略来减少磁盘缓存的锁争用。以下修改是不允许的:
- 不允许修改
NBUF(缓存块总数)的大小 ; - 不允许修改
struct buf的数量,比如设置N个struct buf [NBUF]; - 不允许随意修改锁的命名,本任务涉及到的锁必须以
bcache开头来命名 。
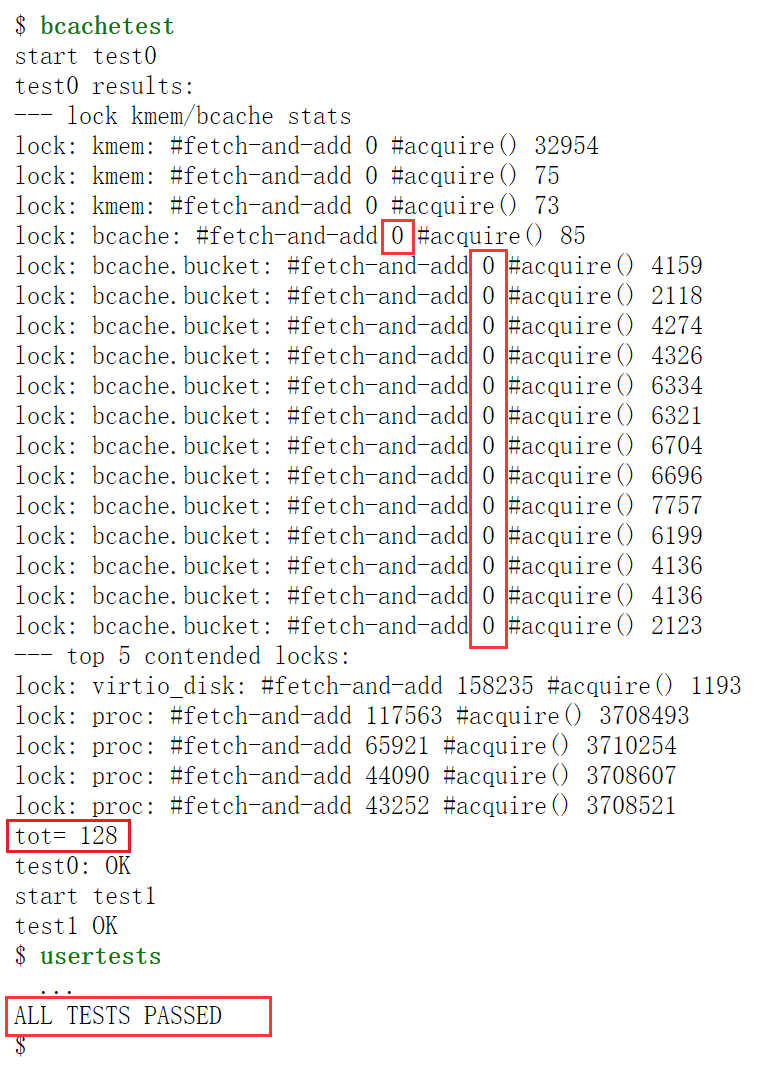
- 理想状态下,
bcachetest中数据块缓存相关的所有锁fetch-and-add的总和应该为0,但本实验中总和tot不超过500即可; - 请修改
bget()和brelse(),使得缓存区并发的查询和释放不容易发生锁争用,比如,不是所有流程都得等bcache.lock; - 同样要求
usertests中的用例全部通过,最后的输出如下(具体数据有所出入):
关测试注意事项
在运行make qemu测试bcachetest和usertests之前, 建议先运行make clean删除fs.img ,以防之前错误的代码把磁盘写坏了,后面即使是改成正确的代码也没法执行。
3.3 测试¶
当完成上述的两个实验后,你需要在xv6-oslab24-hitsz目录下,新建time.txt文件,在该文件中写入你做完这个实验所花费的时间(估算一下就行,单位是小时),只需要写一个整数即可。
在命令行输入 make grade 进行最终测试。